Loupe-gestützte Volltextsuche
Bemerkung
Steht ab MetaModels 2.4 zur Verfügung - benötigt mind. PHP 8.3.
Loupe ist eine Volltextsuchmaschine auf der Basis von SQLite. Die Implementierung orientiert sich u. a. an der Suchmaschine Meilisearch aber mit dem Vorteil, relativ geringe technische Resourcen zu verlangen - PHP und SQLite reichen. Loupe hat verschiedene Features wie Stemming, Ähnlichkeitssuche nach Damerau-Levenshtein, Ranking, Stopp-Wörter u.v.a.m implementiert - siehe Loupe.
Für die Verwendung der Suchmaschine Loupe wurde für MetaModels eine eigene Filterregel gebaut. In den Einstellungen können die zu indexierenden Attribute ausgewählt und Schwellenwerte für Tippfehler angegeben werden.
Die Reihenfolge der zu indexierenden Attribute geht in das Ranking mit ein, d. h. die Attribute sollten nach ihrer Wichtigkeit für die Suche sortiert werden. Diese Option kann mit der Checkbox Ranking nach Reihenfolge der Attribute deaktivieren abgeschaltet werden.
Mit den Schwellenwerten für Tippfehler kann angegeben werden, bei welcher Wortlänge wie viele „Schreibfehler“ enthalten sein dürfen - typische Werte sind z. B. bei einer Wortlänge von fünf Buchstaben ein Schreibfehler und ab neun Buchstaben zwei Schreibfehler.
Die Indexierung der Inhalte der Attribute erfolgt beim Speichern der Datensätze automatisch. Eine komplette Reindexierung erfolgt über ein entsprechendes Icon in der Liste der Filterregeln. Der genaue Ablauf und die notwendigen Einstellungen sind folgend erklärt.
Die Filterregel sollte bei dem Filter an erste Stelle gesetzt werden, weil damit die Reihenfolge der Ergebnisse (Items) bestimmt wird - die Reihenfolge spiegelt das Ranking der Fundstellen wieder (s. u.).
Im Frontend gibt es eine Texteingabe für die Suche. Exakte Wortgruppen können beim Suchstring mit " abgegrenzt werden.
Mit - ist der Ausschluss von Wörtern oder Wortgruppen möglich.
Aktuell werden folgende Attribute indexiert:
Text
Langtext
Übersetzter Text
Übersetzter Langtext
Einzelauswahl [select]
Mehrfachauswahl [tags]
Sortierung und Ausgabe
Damit die Datensätze (Items) nach der Relevanz (Score) der Suche sortiert werden, muss die Filterregel im Filter an erster Stelle stehen. Die erste Filterregel, die eine Liste mit Ids der Items liefert, bestimmt immer die grundlegende Reihenfolge der auszugebenden Datensätze. Das bedeutet, dass man nach der Filterregel Loupe eine Filterregel „Eigenes SQL“ anlegen kann die eine Sortierung liefert, wenn Loupe gar nicht angesprochen wird - z. B. nach Name. Zudem darf in der Listeneinstellung keine individuelle Sortierung eingestellt sein - diese würde die Reihenfolge immer überschreiben.
Ist die Filterung mit Loupe in dem Filter vorhanden, ist in dem Ausgabearray der Datensätze ein Key loupe vorhanden.
Bei einer Filterung mit Loupe ist in dem Knoten die berechnete Relevanz des Datensatzes als score angegeben.
1<?php if ($arrItem['loupe']['score'] ?? false): ?>
2 <p>Score: <?= \Contao\System::getFormattedNumber($arrItem['loupe']['score'], 4) ?></p>
3<?php endif; ?>
Bei den Einstellungen der Filterregel kann die Option „Hervorhebung der Suchbegriffe“ aktiviert werden. Ist dies der
Fall, wird zusätzlich zum Sore noch im Knoten formattedHits die Attribute ausgegeben, bei denen durch die Suche
Fundstellen ermittelt werden konnten. Die Fundstellen sind inklusive einer Markierung in dem Array vorhanden.
Als Beispiel der folgende Screenshot - hier wurde nach „Moin“ gesucht und es gab zwei Fundstellen. Obwohl beide Datensätze das Wort „Moin“ in der selben Schreibweise beinhalten, ist das Scoring beim zweiten Datensatz niedriger. Das ergibt sich aus der eingestellten Reihenfolge der Attribute in der Filterregel erst Vorname (firstname) und dann Name (name).

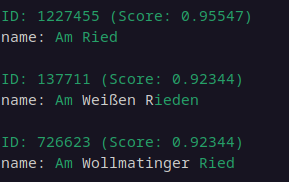
Neben der Ausgabe im FE kann - z. B. für ein Check des Indexes - die Suche auch per Konsole durchgeführt werden; als Parameter werden die ID der Filterregel und der Suchstring übergeben.
php contao/bin/console metamodels:loupe:test-index 11 "Am Ried"
Die Ausgabe beinhaltet neben der Index-ID und dem Score auch die Angabe des Attributs und eine farbliche Kennzeichnung des Matches.
Einstellung von Stopp-Wörtern
Bei der Suche können einzelne Wörter definiert werden, die bei der Suche und Ranking übergangen werden sollen - mehr dazu bei Loupe.
Die Behandlung der Stopp-Wörter bezieht auch die Behandlung von Wörtern mit ein, die z. B. per
Stemming gebildet werden. Möchte man zum
Beispiel vermeiden, dass bei der Sucheingabe von forms auch nach dem häufig vorkommenden for gesucht wird,
sollte man for in der Liste der Stopp-Wörter eintragen.
Die Stopp-Wörter werden nicht beim Indexieren ausgeschlossen, sondern erst bei der Suche. Wenn ein Stopp-Wort allein
als solches eingegeben wird wie for, wird aber dennoch danach gesucht.
Die Liste der Stopp-Wörter legt man in der eigenen config.yml ab. Für jede Sprache die in dem MetaModel angelegt
ist, kann ein eigener Bereich definiert werden - für alle einsprachigen Model kommt die Liste unter default.
Folgend ein Beispiel:
1# config/config.yml
2meta_models_filter_loupe:
3 stop_words:
4 default:
5 - ein
6 - der
7 - die
8 - das
9 - für
10 en:
11 - a
12 - an
13 - by
14 - for
15 de:
16 - der
17 - die
18 - das
19 - ein
20 - für
Ablauf der Indexierung und Einstellungen
Wenn ein Datensatz mit geänderten Inhalten der zu indexierenden Attribute gespeichert oder in der Filterregel die Reindexierung gestartet wird, erfolgt die Abarbeitung nicht direkt in dem Web-Aufruf (synchron), sondern es wird eine Meldung an den Symfony-Messenger für die asynchrone Verarbeitung übergeben. Mehr zu dem Thema im Contao-Handbuch oder Vortrag zur CK23.
Gespeichert werden die „Messenger-Aufträge“ in der Tabelle tl_message_queue - ggf. wird diese neu erzeugt.
Aktuell muss für die Verarbeitung der Messenger-Jobs eine
„Transportkonfiguration“
in der config.yml angelegt sein - folgend für Loupe:
1# config/config.yml
2framework:
3 messenger:
4 routing:
5 MetaModels\FilterLoupe\*: contao_prio_high
6# Alternativ: separate Einstellung möglich
7# MetaModels\FilterLoupe\Messenger\IndexMessage: contao_prio_high
8# MetaModels\FilterLoupe\Messenger\ReIndexMessage: contao_prio_normal
In einer der folgenden Versionen nehmen wir eine vollständige Anbindung an die Contao-Implementierung vor, so dass das nicht mehr notwendig sein wird.
Der Messenger wiederum wartet darauf, für die weitere Verarbeitung angestoßen zu werden. Das erfolgt mit dem Cron-Job von Contao - dieser sollte entsprechend eingerichtet sein.
Während der Indexierung wird für jede Filterregel ein eigener Index als SQLite-DB angelegt - bei mehrsprachigen Models
bzw. mehrsprachigen Attributen gibt es wiederum für jede Sprache einen eigenen Index. Die Daten liegen unter
var/mm_loupe_index/<id-Loupe-Filterregel>/.
Die Reindexierung kann nach Neuerstellung der Filterregel oder bei Änderungen der Einstellungen manuell angestoßen
werden. Dabei wird die Index-Datenbank vorher geleert. Der Start erfolgt über das Icon in der Liste der Filterregeln
oder über Konsole - mit dem optionalen Parameter -p kann die Anzahl der Items, die je Eintrag in der
tl_message_queue abgearbeitet werden sollen, angepasst werden; Standard ist 50.
php contao/bin/console metamodels:loupe:reindex -p 1000